Übersicht Produkte
Pflege
Pflege
LINDERA ist ein Medizinprodukt der Klasse I nach MDD.


Klinik
Klinik
In Kürze verfügbar


Tech
Tech
Integration





Die Age Tech Map Germany: Fachliche Kompetenz und Innovation in der Pflege
21. März 2024 von Celine Heinzel
Die Pflege älterer Menschen ist ein Akt der Menschlichkeit, der…
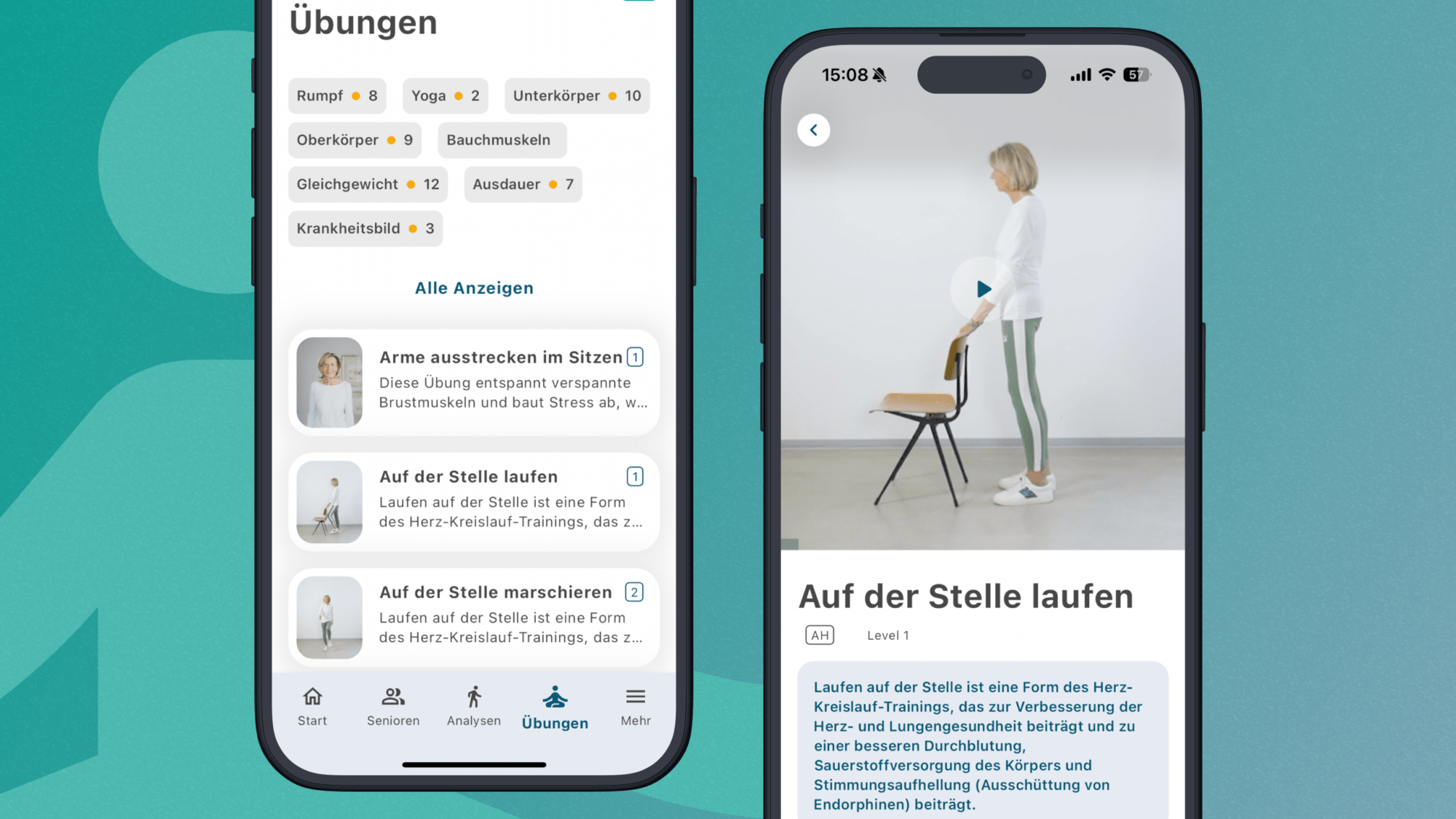
Ein neues Kapitel der LINDERA Mobilitätsanalyse per App: Integrierte Übungen für Senioren
13. März 2024 von Sofia Kappa
Mit integrierten Übungen schlagen wir ein neues Kapitel in unserer…
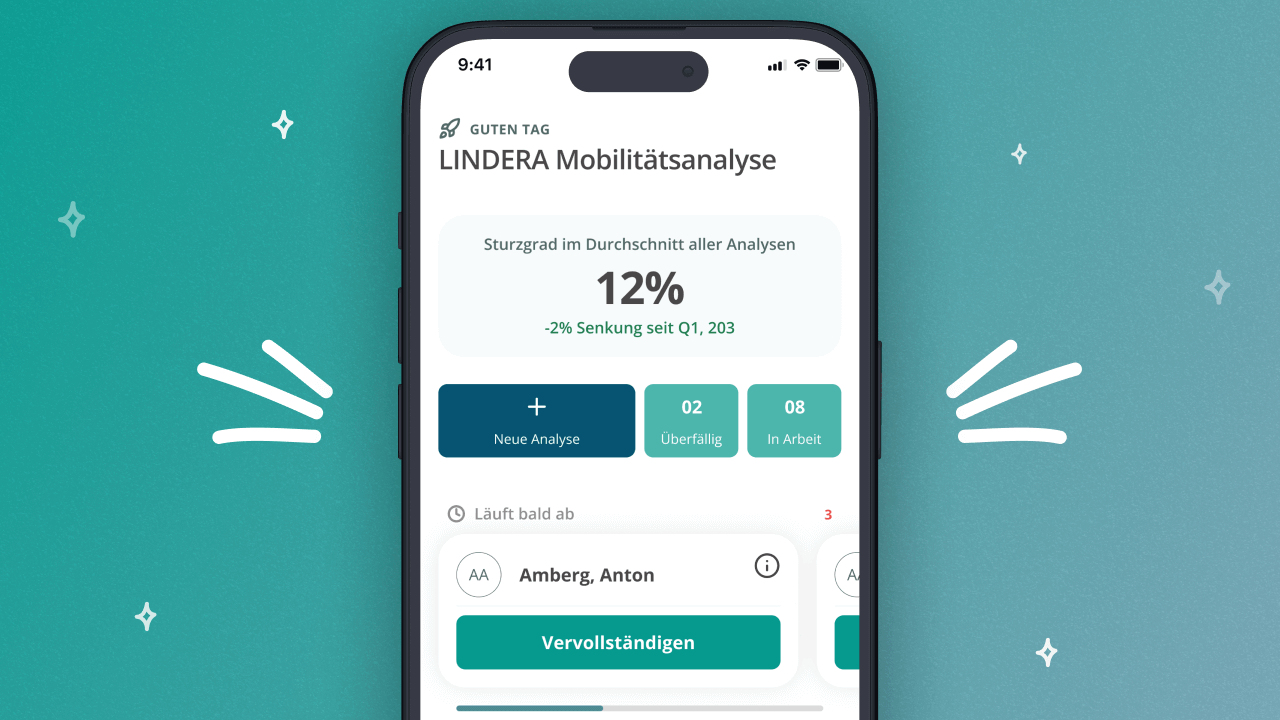
Neuerungen in der LINDERA Mobilitätsanalyse per App: Fachliche Kompetenz trifft digitale Innovation
22. Februar 2024 von Sofia Kappa
Was sind die Neuerungen in der LINDERA Mobilitätsanalyse per App?…

Meister des Wandels in der Pflege – Mit dem Deutschen Service Preis ausgezeichnet
16. Februar 2024 von Menia Ettrich
Im Herzen Berlins, in der Bertelsmann Repräsentanz, wurde gestern ein…

Cheesy Moment: Auszeichnung als CHIP Digital Innovator 2024
07. Februar 2024 von Diana Heinrichs
Innovative Technologie im Gesundheitswesen: LINDERA als Vorreiter In einem bemerkenswerten…

Wissenschaft: LINDERAs KI bei der Deutschen Gesellschaft für Orthopädie und Unfallchirurgie
17. Januar 2024 von Sónia Alves
Wissenschaftlicher Ansatz in der Sturzprävention Marie Kura, Mitglied des LINDERA…

Altenpflege x KI: Was ich vom Web Summit zum Thema Ganganalysen und Sturzprävention mitgenommen habe
22. Dezember 2023 von Sofia Kappa
Wie passen Altenpflege, KI und der Web Summit zusammen? 🧐…

WDR Lokalzeit Münsterland: LINDERA App in Bocholt im Test
15. Dezember 2023 von Menia Ettrich
In der gestrigen Ausgabe der WDR Lokalzeit Münsterland ab Minute 6.18 wird…

Potenziale von Computer Vision-KI (CV) in der Altenpflege: Wie Sie den Erfolg messen (KPIs)
11. Dezember 2023 von Diana Heinrichs
In der Altenpflege bietet eine Computer Vision-KI (CV) ein immenses…

Qualitätsmanagement 2.0 bei Pflegemotive in Winsen (Aller)
08. Dezember 2023 von Silvie Heeger
Qualitätsmanagement in der Pflege – Innovative Partnerschaft zeigt die Relevanz…

Pflegedienst Bocholt der AZURIT Rohr GmbH: Ambulante Pflege-Pioniere setzen mit DiPA neue Maßstäbe
20. November 2023 von Menia Ettrich
Ambulante Pflege-Pioniere setzen mit DiPA neue Maßstäbe – In einem herausfordernden Pflegeumfeld, in dem viele über den Fachkräftemangel sprechen, schreitet das 8-köpfige Team des AZURIT Ambulanten Pflegedienstes Bocholt mit seinen 37 Pflegebedürftigen proaktiv voran.
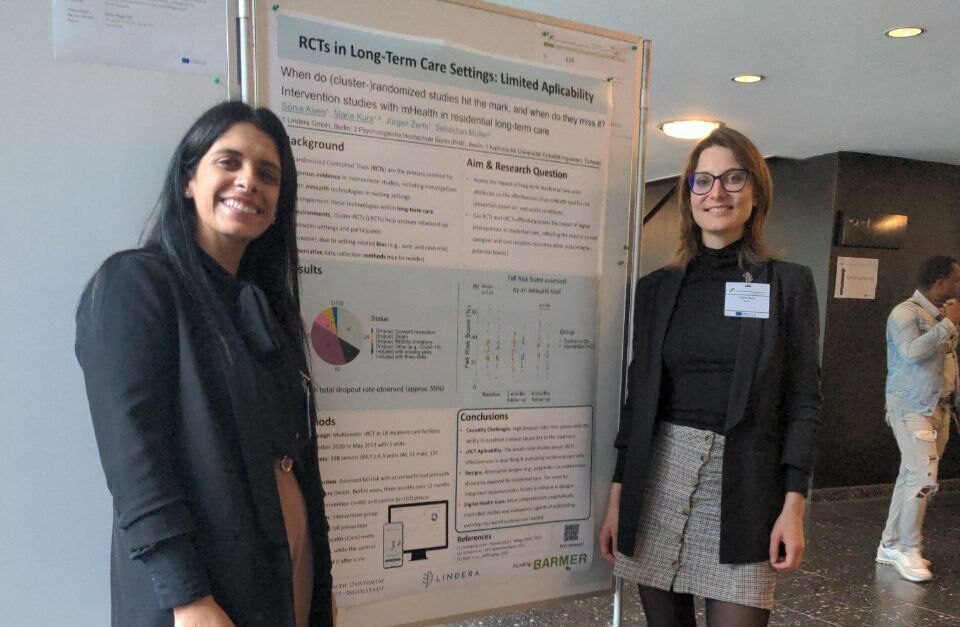
DKVF-Konferenz: Einblicke in Cluster-RCTs in der Altenpflege
13. November 2023 von Sónia Alves
Ergebnisse und Grenzen der Forschung in der Altenpflege Hier meldet…

Eine Reise jenseits von „Go“ – Tanz in die Zukunft: Kollaborative Innovation zwischen KI und Menschen
07. November 2023 von Bowen Zhou
Kollaborative Innovation zwischen KI und Menschen: Eine spannende Reise jenseits…

AD Germany zeichnet Pournoir aus: Wie Douman Pour unsere KI-Werkstatt für die Zukunft der Pflege schuf
von Anke Johansen
AD Germany zeichnet Pournoir aus: KI-Werkstatt in Kreuzberg

Could ChatGPT Become A Decision Support Tool For Medical Practitioners?
24. Oktober 2023 von Diana Heinrichs
Digital Meets Real: A doctor or healthcare professional interacting with a holographic or digital interface, representing AI tools like ChatGPT.

BILD Vorsorgegipfel x Digitale Gesundheitsinnovationen: Die Zukunft der Medizin ist hier!
20. Oktober 2023 von Diana Heinrichs
BILD Dir Deine Meinung!? Gestern war ich in einem besonderen…

Fahrradfahren Lernen und der Umgang mit digitalen Hilfsmitteln in der Pflege: Eine Parallele des Lernens
16. Oktober 2023 von Silvie Heeger
Stürze sind nicht nur ein Thema im Alter. Was sind die Parallelen zu unseren Kindertagen?

Korian Haus Gartenstadt in Berlin: Schritt für Schritt zur KI-Revolution im Pflegealltag
09. Oktober 2023 von Silvie Heeger
Das Korian Haus Gartenstadt in Berlin arbeitet seit 2019 eng mit der LINDERA App zusammen, um mithilfe von KI den Pflegealltag zu optimieren.

LINDERA auf dem DNQP Netzwerktreffen: KI-basierte Lösung zur Sturzprophylaxe
02. Oktober 2023 von Silvie Heeger
Neue Erkenntnisse und Praxisumsetzung des Expertenstandards Sturzprophylaxe standen im Mittelpunkt des DNQP Netzwerktreffens. Erfahren Sie, wie diese Einsichten die Weiterentwicklung der LINDERA Mobilitätsanalyse zur Sturzprävention beeinflussen.

Wir sind heute nicht auf dem Deutschen Pflegetag – schon wieder nicht.
28. September 2023 von Silvie Heeger
Der Deutsche Pflegetag ist mehr als eine Veranstaltung – er ist die Bühne für tiefgreifende Veränderungen in der Pflegebranche.

Warum Tech-Giganten den Anschluss an die „Langlebigkeit-Ökonomie“ verpassen
25. September 2023 von Diana Heinrichs
Laut New York Times verpassen die Tech-Giganten die Langlebigkeit-Ökonomie.

Wir treffen uns in Nürnberg – ConSozial 2023
14. September 2023 von Silvie Heeger
LINDERA auf ConSozial 2023 – Wir haben tolle Neuigkeiten! Auch…

LINDERA Teamtage: Eine Reise zu Innovation und Zusammenarbeit
13. September 2023 von Reza Rezvani
Unsere Teamtage bei LINDERA – Eine Reise zu Innovation und…

Wie sieht die Physiotherapie die LINDERA Mobilitätsanalyse per App?
05. September 2023 von Sofia Kappa
Bevor ich auf die Bedeutung der Ganganalyse in der Physiotherapie…

Unser menschliches Betriebssystem: Die Verschmelzung der physischen und digitalen Selbst
04. September 2023 von Diana Heinrichs
Unser menschliches Betriebssystem: Die Verschmelzung der physischen und digitalen Selbst…
Digitalisierung in der Altenpflege: Chancen, Herausforderungen und ein Fahrplan
19. August 2023 von Reza Rezvani
Chance oder Fluch? Und wie sieht ein Fahrplan zur Digitalisierung…

Beeindruckende Fortschritte mit der LINDERA Mobilitätsanalyse App: Zahlen, Daten und Fakten
15. August 2023 von Silvie Heeger
Die letzten Monate waren für uns bei LINDERA geprägt von…

LINDERA: Ein Sprungbrett für Gründer:innen und Innovator:innen
24. Juli 2023 von Diana Heinrichs
Was ist ein Sprungbrett für Gründer:innen und Innovator:innen? Als Gründerin…

Schutz von Leben und Daten im Zeitalter der digitalen Pflege
21. Juli 2023 von Peter Woodcraft
Informationssicherheit dient dem Schutz von Leben und Daten im digitalen Zeitalter.
Digital Health Szene in Deutschland: Auf der Suche nach Stabilität und Wachstum
12. Juli 2023 von Diana Heinrichs
Digital Health in Deutschland: Was vom Hype übrig geblieben ist und was es brauchst, um die Zukunft zu gestalten.

KI in der Medizin: zweites europäisches Patent für LINDERA
11. Juli 2023 von Reza Rezvani
Berliner Health-Tech-Unternehmen LINDERA erhält zweites europäisches Patent Das Patent schützt…

Diverse Lerntypen bei ML erforschen: Kein Skynet in absehbarer Zeit?
30. Juni 2023 von Steffen Temme
Einführung Es gibt diverse Lerntypen bei Machine Learning | Als…

KI x Bike Fitting: LINDERA meets Eurobike Frankfurt 2023
20. Juni 2023 von Sofia Kappa
LINDERA ist in der Gesundheits- und Medizintechnikbranche bekannt. Unsere 3D-Motion…

Gemeinsam aktiv gegen Demenz: Die Rolle von Bewegung in der Betreuung und Pflege
14. Juni 2023 von Silvie Heeger
Bewegung und Pflege bei Demenz

Digitale Sturzprophylaxe und die Zukunft der Versorgung: Ein Podcast mit Christoph Schneeweiß von CareTable.de
09. Juni 2023 von Diana Heinrichs
Die digitale Zukunft der Versorgung – Kürzlich kam Christoph Schneeweiß,…

Mut zur Veränderung für eine bessere Pflege – Benediktbeurer Zukunftsgespräche 2023
25. Mai 2023 von Diana Heinrichs
Die Veränderung für eine bessere Pflege – Auf Einladung der…

The Changing Landscape of Medicine: Five Insights from Middlemarch to AI
17. Mai 2023 von Diana Heinrichs
The changing landscape of medicine – George Eliot’s classic novel,…

So war die Altenpflegemesse 2023 für uns: 5 Eindrücke
09. Mai 2023 von Silvie Heeger
Altenpflegemesse 2023 – Vom 25. bis zum 27. April…

LINDERA und Krankenkasse KNAPPSCHAFT setzen bundesweit App zur Sturzprävention ein
04. Mai 2023 von Silvie Heeger
KNAPPSCHAFT fördert die Mobilitätsanalyse – Der Einsatz von Künstlicher Intelligenz…
Unsere Partner
Führende Krankenkassen und IT Anbieter für die Pflege- und Gesundheitsbranche gehören zu unseren Partnern.




