
Es ist bemerkenswert, wie gut das Höhlengleichnis von Plato unser Schicksal als Menschen beschreibt, Wissen über die Welt um uns herum nur mit einem Grad an Unsicherheit zu erlangen. Dieser Grad an Unsicherheit ist niemals Null. Das liegt daran, dass wir die Welt durch unsere natürlichen Sinne beobachten, während unser Gehirn diese Beobachtungen interpretiert und dann daraus immer komplexere Wissenssysteme wie Kultur, Philosophie und Wissenschaft formt.

Dieses berühmte Gleichnis veranschaulicht auch sehr gut unsere Situation in der Datenwissenschaft. Kürzlich schrieb Dr. Cassie Kozyrkov, Chief Decision Scientist bei Google, einen spannenden Blog-Beitrag über das, was sie die „traurigste Gleichung in der Datenwissenschaft“ nennt:
Daten + Annahmen = Schlussfolgerung.
Diese Gleichung ist recht einfach, aber im Wesentlichen tief und wahr, wenn es um statistische Rückschlüsse und Datenwissenschaft geht. Wir nehmen Daten, setzen einige Annahmen oben drauf und dies ermöglicht uns Vorhersagen über bisher unbekannte Datenpunkte oder zukünftige Beobachtungen. Es gibt ausdrücklich keine Möglichkeit, die Annahmen aus dieser Gleichung herauszunehmen. Im Wesentlichen führt unser Gehirn ebenfalls „Datenwissenschaft“ durch, nur dass diese viel komplexer ist. Obwohl das Gehirn verschiedene Inferenzalgorithmen auf sehr unterschiedlichen Eingabedaten (Sehen, Hören, Riechen, Tasten) parallel ausführt und all diese Beobachtungen in ein aussagekräftiges Gesamtbild integriert, gilt die obige Gleichung immer noch. Letztendlich erfolgt die Interpretation der „Daten“ durch unsere Sinne im Gehirn und die Rückschlüsse auf diese Daten nicht ohne Annahmen.
Alle Entscheidungen basieren auf Annahmen. Als ich meinen Besuch beim Desert Fest Stoner Rock Festival 2020 in Berlin geplant hatte, ging ich davon aus, dass keine weltweite Pandemie zur Absage aller Großveranstaltungen führen würde. Wenn ich mich für Schokoladeneis entscheide, gehe ich davon aus, dass es sehr gut schmecken wird. Wenn ich mich entscheide, ohne Regenschirm auszugehen, habe ich angenommen, dass es nicht regnen wird. Überall gibt es Annahmen. Noch einmal würde ich gerne Cassie Kozyrkov zitieren, sie bringt es auf dem Punkt:
„Zwei Personen können aus den gleichen Daten zu völlig unterschiedlichen, gültigen Schlussfolgerungen kommen! Alles, was es braucht, sind unterschiedliche Annahmen.“
Quelle.
Von Katzen und Nicht-Katzen: Ein Experiment in Datenwissenschaften
Dennoch neigen wir in der Datenwissenschaft oft dazu, Probleme zu technologiezentriert anzugehen. Ich meine damit die Tendenz, „glänzende“ Algorithmen zu entwickeln, um jede Entscheidung zu automatisieren und dann ganz am Ende, wenn überhaupt, über die Entscheidungen, Ergebnisse und Ziele nachzudenken.
Hier ist es mein Wunsch, Sie davon zu überzeugen, dass es eine sehr nützliche Disziplin gibt, die es uns ermöglicht, zuerst die Ziele einer Entscheidung gründlich zu definieren und dann ein grafisches Bild der gesamten Entscheidungsprozesse zu erstellen. Am Ende, wenn das Bild vollständig ist, gehen wir zu den Mikro-Entscheidungen über, welches Technologie-/Analyse-/Statistik-Werkzeug wir an jeder Kante einfügen möchten, die zwei Knoten des Entscheidungsdiagramms verbindet.
Aber lassen Sie mich zunächst versuchen, Sie visuell davon zu überzeugen, warum die Datenwissenschaft, Künstliche Intelligenz (KI) oder Maschinelles Lernen (ML) alleine nicht ausreichen, um verantwortungsvolle Entscheidungen zu treffen, insbesondere im Bereich der Gesundheitswissenschaft und der Gesundheitstechnologie. Dafür lassen Sie uns ein Spiel spielen, das ich von einem anderen inspirierenden Blog-Post von Cassie Kozyrkov ausgeliehen habe: In diesem Spiel zeige ich Ihnen sechs Bilder mit Tieren (Abb. 2). Ihre Aufgabe besteht darin, das Bild mit dem Etikett „Katze“ oder „keine Katze“ zu versehen. Und ich werde gemein sein und Ihnen nur erlauben, genau eines dieser beiden Etiketten pro Bild zu wählen, und nichts dazwischen.

Es scheint ganz einfach für uns, die Bilder 1 bis 5 zu beschriften. Aber die Dinge werden kompliziert, sobald wir bei Bild 6 sind. Hier sind wir versucht, so etwas wie „Wildkatze“ oder „große Katze“ oder „etwas in der Familie der Katzen“ zu wählen. Aber da ich gemein war und nur erlaubt habe, Katze oder keine Katze auf die Bilder zu setzen, stecken Sie in Ihrer Entscheidung fest … „Katze oder keine Katze, das ist die Frage“, würde der (Katzen-) Hamlet sagen. Unser Freund, der KI-Algorithmus, wird sich nicht viel mit dieser Frage beschäftigen und nur eine Entscheidung nach den Bildmerkmalen treffen, die er während des Trainings auf einem bestimmten Datensatz auswendig gelernt hatte. Es könnte sich hier für eine der Etiketten entscheiden, mit spezifischem Prozentwert an Überzeugung vielleicht, aber nichts dazwischen.
Und das ist im Wesentlichen unser Dilemma: Wir müssen zuerst das Ziel dieser Entscheidung klären. Andernfalls macht die ganze Entscheidung keinen Sinn. Wenn wir das Ziel haben, nur „Schmusekätzchen“ zu erkennen, dann sollten wir vielleicht entweder den Tiger in Bild sechs aus der Katzenklasse ausschließen oder die Beschriftung an so etwas wie „Katze zum Kuscheln“ versus „Katze nicht zum Kuscheln“ anpassen. Andernfalls, wenn Sie jemand wie der Tiger King sind, dann könnten Sie sogar den Tiger in die Kategorie „Katze zum Kuscheln“ einschließen.
Erklärbare KI: Wie ein Algorithmus entscheidet
Neben der Frage des nicht eindeutigen Ziels gibt es ein weiteres großes Problem, den KI-Algorithmus nur um seiner selbst Willen anzuwenden. Das ist das sogenannte Shortcut-Lernen. Dies kann katastrophale Auswirkungen haben, wenn es unentdeckt bleibt, insbesondere im medizinischen Bereich. Aber es gibt eine Lösung am Horizont, die von Forscher*innen im Bereich der erklärbaren KI kontinuierlich weiterentwickelt wird. Forscher*innen der Technischen Universität (TU) Berlin und des Fraunhofer Heinrich-Hertz-Instituts für Videokodierung und Maschinelles Lernen entwickelten sehr nützliche Werkzeuge, um bildbasierte KI-Entscheidungen zu bewerten und die Entscheidung dann auf die Bildmerkmale zurückzuverfolgen, die zu der Entscheidung führten. In einer kürzlich erschienenen Veröffentlichung diskutierten sie einige ihrer inspirierenden Analyseergebnisse. Ein besonderes Beispiel ist ein KI-Algorithmus, der trainiert wurde, um Pferde in Bildern zu klassifizieren. Die Anwendung ihres Entscheidungsbewertungswerkzeugs hat eindeutig gezeigt, dass der Algorithmus gelernt hatte, das Pferd im Bild allein nach der Existenz des Quellen-Tags zu klassifizieren (siehe Abb. 3). Einige weitere Beispiele werden auf der Seite der TU Berlin vorgestellt und diskutiert.
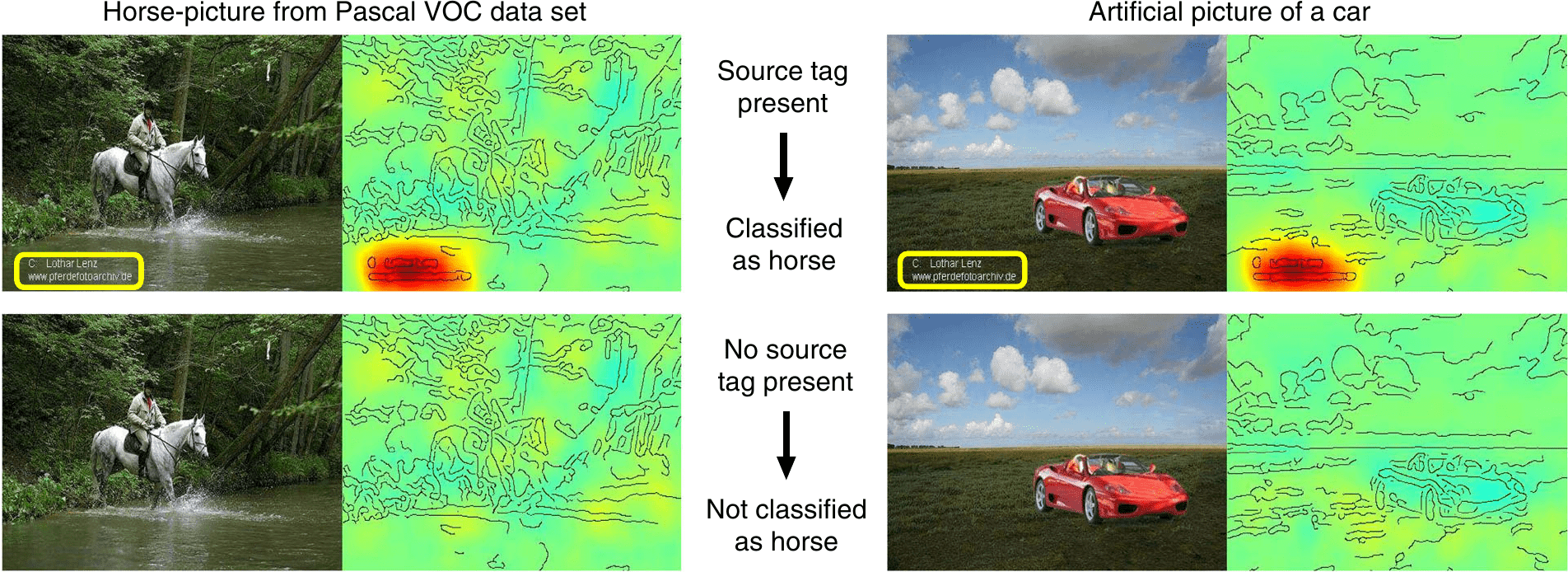
©Nature Communications/CC BY
Meiner Ansicht nach zeigen diese Beispiele, die die Autor*innen der obigen Publikation diskutieren, eine „Übergeneralisierung“ der erlernten Darstellung. Wie ich in meinen letzten Blog-Beiträgen zur Information Bottleneck Theorie zum Prozess des Lernens in tiefen neuronalen Netzen (Teil 1 und Teil 2) besprochen habe, beinhaltet dieser Lernprozess zwei Phasen. Die erste Phase ist nur eine Anpassung der Eingabedaten (Bilder) an entsprechende Klassenbeschriftungen (Pferd). Die zweite Phase ist durch die Kompression der kodierten Informationen innerhalb des neuronalen Netzwerks gekennzeichnet. Im Wesentlichen hat der Algorithmus, der die Bilder als ein Pferd klassifiziert, nur eine sehr optimale Abkürzungsfunktion gefunden, die es ihm ermöglicht, die Bilder zu klassifizieren. Diese Abkürzungsfunktion ist der Quellen-Tag. Es muss hier jedoch angemerkt werden, dass das obige Beispiel (Pferde-Klassifikation) kein neuronales Netzwerk ist, sondern ein sogenannter “Fisher Vector-Classifier“. Dennoch wird bei der Verwendung von Fisher-Vektoren zum Extrahieren lokaler Eigenschaften aus Bildern für die Klassifizierung im Wesentlichen eine Komprimierung/Reduktion von kodierten Informationen angewendet, um Bilder nach verschiedenen Klassen (Pferd/kein Pferd) zu beschreiben. In diesem Sinne gilt nach wie vor das Problem des Shortcut-Lernens.
Wer ist Schuld an den Entscheidungen des KI-Algorithmus
Wer ist also hier schuld? Ist es der ausgebildete KI-Algorithmus? Sind es die Daten? Oder beides? Meiner Meinung nach ist keiner von ihnen schuld. Wir sind schuld, sonst nichts. Wir haben den Algorithmus erstellt, die zugrunde liegenden Daten erstellt/kuratiert, wir haben die Lernmechanismen entwickelt und angewendet, wir haben den Lernprozess überwacht, und schließlich sind wir schuld, wenn wir den Algorithmus ohne Bewertung seiner „guten“ und „schlechten“ Entscheidungen einsetzen.
Die Dinge sind noch schlimmer und Sie müssen jetzt sehr stark sein. Ich muss Ihnen die Illusion nehmen zu denken, dass wir Menschen nicht das Problem des Shortcut-Lernens haben. Obwohl unser Gehirn so viel komplexer ist als unsere aktuellen KI-Algorithmen, fallen wir immer noch auf „Abkürzungen“ herein. Wir spielen auch „Überkompression/Übergeneralisierung“. Denken Sie nur an weit verbreitete rassistische und diskriminierende Vorurteile, die auch heute noch im Umlauf sind, wie „Frauen können nicht Auto fahren„, „Mexikaner sind Kriminelle“ oder Verschwörungsmythen wie „5G ist für Corona verantwortlich“.
Die vier Säulen des Gesunden Menschenverstandes
Trotz dieser verheerenden Botschaft gibt es Hoffnung für uns. Die Evolution hat uns mit gesundem Menschenverstand gesegnet, den wir nutzen können und müssen, wenn wir nicht auf die gemütlichen Abkürzungen hereinfallen wollen. Yann LeCun, einer der Gründerväter des tiefen Maschinellen Lernens in neuronalen Netzen, betrachtet beispielsweise unseren menschlichen Verstand als auf vier Hauptfähigkeiten aufgebaut, die in Abb. 4 dargestellt sind. Die uns zur Verfügung stehenden aktuellen KI-Algorithmen scheitern in allen bis auf ein Element dieses gesunden Menschenverstandes (siehe Abb. 4).
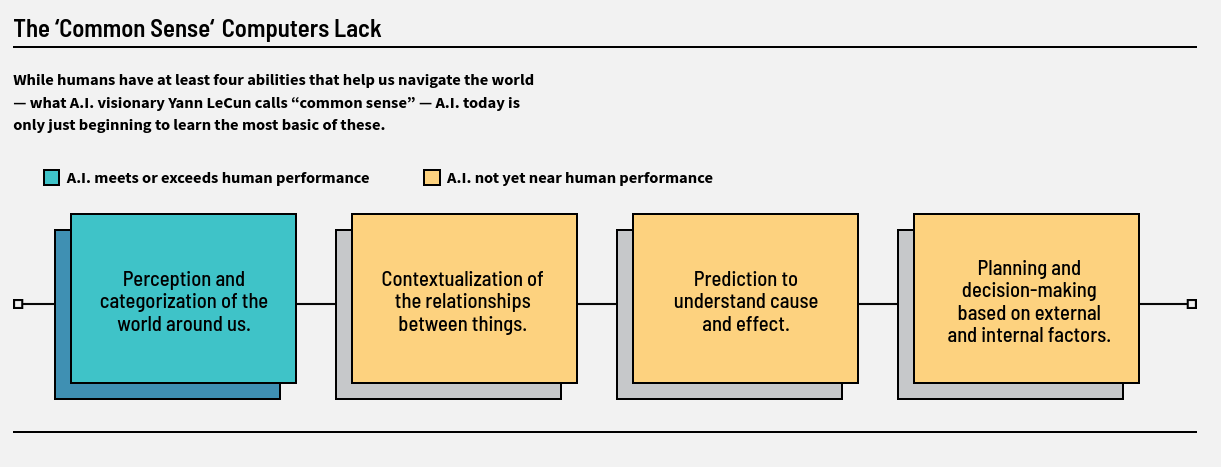
Die besonders wichtigen Elemente dieses gesunden Menschenverstandes für die Entscheidungsfindung in einer komplexen und unsicheren Welt wie unserer sind diejenigen, in denen die aktuellen KI-Algorithmen scheitern. Diese sind in der Abbildung oben auf gelbem Hintergrund dargestellt. Ich würde sogar so weit gehen zu sagen, dass, obwohl alle Menschen die Fähigkeit haben, Kontextualisierung von Beziehungen, Verständnis von Ursache und Wirkung, Planung und Entscheidungsfindung zu nutzen, die meisten diese wertvollen Fähigkeiten nicht nutzen. Stattdessen fallen wir zu oft auf Wahrnehmung und Kategorisierung zurück, da es so bequem ist und die anderen drei im Alltag zu kompliziert sind. Das ist der Grund für unsere oben dargestellten Vorurteile.
Was ist Decision Intelligence?
Die vier Säulen des gesunden Menschenverstandes stehen auch im Mittelpunkt einer neuen Disziplin für systematische und rationale Entscheidungsfindung in komplexen politischen, wirtschaftlichen und vielen anderen Systemen. Dies ist die Disziplin der Decision Intelligence (DI). In ihrem sehr guten Einführungsbeitrag zur DI bezeichnete Cassie Kozyrkov diese Disziplin auch als Data Science++ oder Machine Learning++, da es KI mit gesundem Menschenverstand zu erweitern versucht, um bessere Entscheidungen zu treffen.
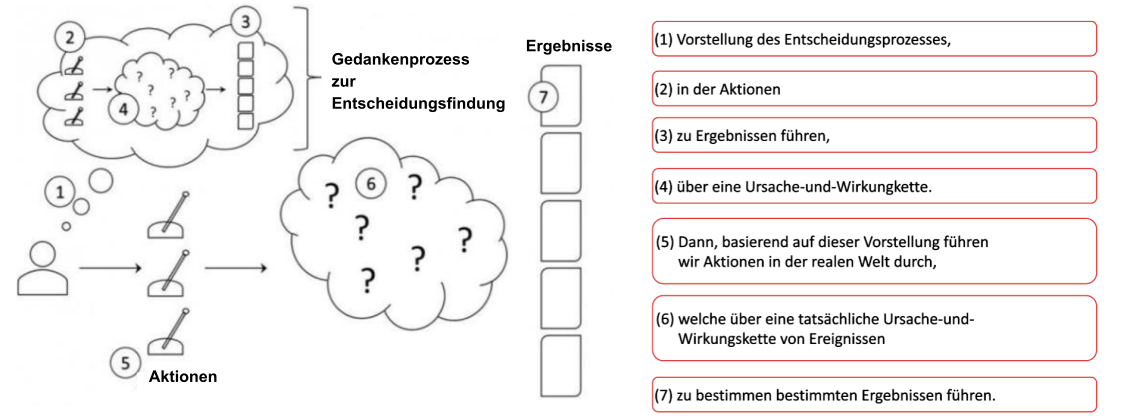
Wir können DI besser verstehen, wenn wir zuerst im Prinzip betrachten, was eine Entscheidung ist und wie wir als Menschen Entscheidungen treffen, von der Vorstellung des Entscheidungsprozesses in unserem Kopf bis hin zu den Maßnahmen, die wir in der realen Welt ergreifen, was zu echten Ergebnissen führt (siehe Abb. 5).
Aus diesem Schema der Entscheidungsfindung können wir unser eigenes Entscheidungsmodell für jedes Projekt grafisch aufbauen. In Abb. 6 wird eine schematische Vorlage dieser grafischen Darstellung gezeigt. Lorien Pratt, eine der Hauptgründerinnen von DI als Disziplin, hat diese Vorlage als „Causal Decision Diagram” (CDD) bezeichnet. Die CDD eines bestimmten Projekts besteht aus einfachen Bausteinen und diese sind durch unsere Annahmen über das Projekt und die zu treffenden Entscheidungen miteinander verbunden.
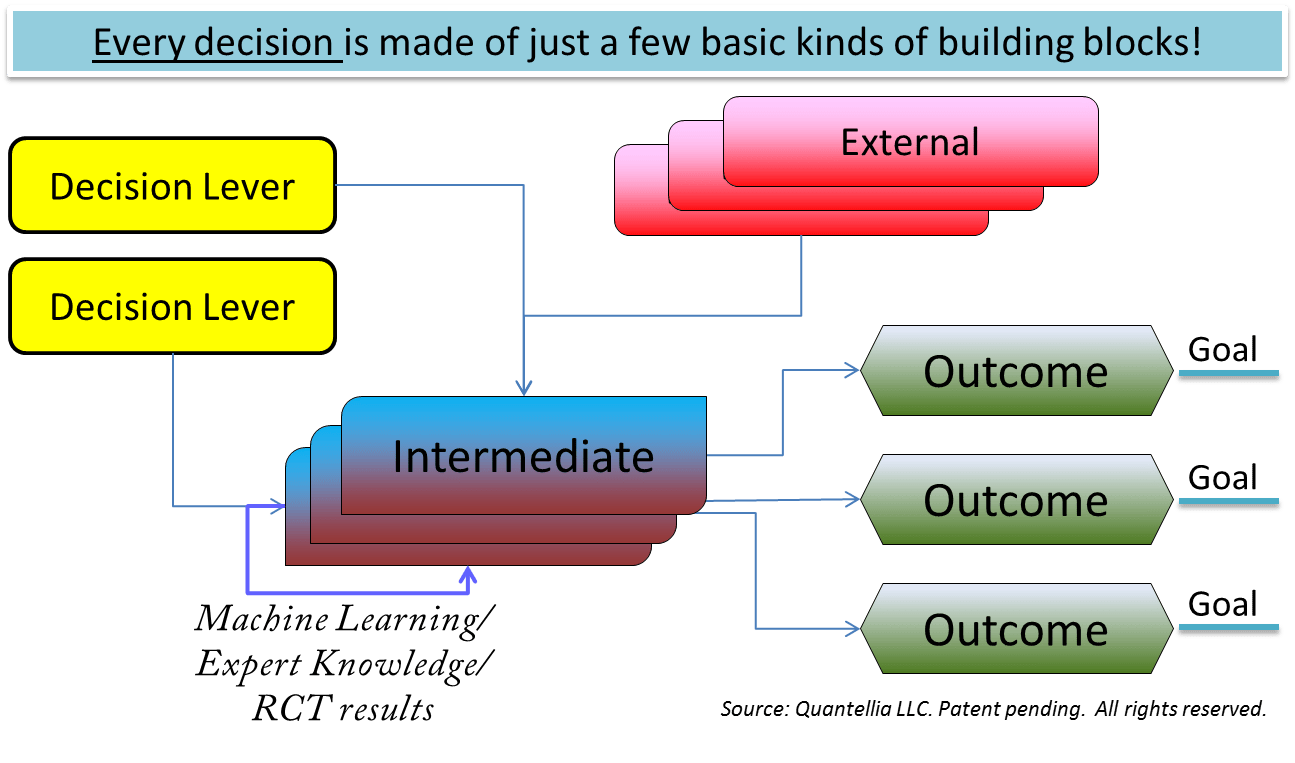
Wenn die CDD erstellt wurde, definieren wir in erster Linie die Ziele. Dann können die Entscheidungshebel spezifische Handlungsoptionen sein, z. B. mögliche medizinische Behandlungen. Die externen Effekte werden von der Umgebung festgelegt. Dies kann das Budget für das Projekt, das IT-System der Kliniken, etc. sein. Zwischenprodukte sind potenzielle direkte oder indirekte Auswirkungen der Entscheidungshebel, z. B. Vorteile spezifischer medizinischer Behandlungen, Nebenwirkungen von Entscheidungen usw. Schließlich erfolgen die Ergebnisse, sowohl die Erwünschten als auch die Unerwünschten.
Das CDD-Schema zeigt deutlich den ganzheitlichen Charakter von DI. An jeder Kante des Diagramms könnten wir einen KI-Algorithmus einfügen, um datenbasiertes Wissen zu generieren, damit wir eine fundiertere Entscheidung treffen können. Es muss jedoch angemerkt werden, dass das Einfügen eines KI-Algorithmus nicht obligatorisch ist, sondern nur von der Art der spezifischen Kante zwischen den einzelnen Knoten des Graphen abhängt. Wenn das Verhältnis zwischen der Aktion und dem potenziellen Ergebnis faktisch ist (Domänen-Expertenwissen), dann besteht keine Notwendigkeit für KI. Stattdessen werden uns die Fakten informieren. Wenn die Beziehung zwischen den Knoten von analytischem/mathematischem Typ ist, wird die mathematische Analyse unseren Weg zur Entscheidung an diesem Punkt des Diagramms informieren. Wenn unser Wissen an einem Punkt des CDD ungewiss ist, dann wird uns eine datenbasierte statistische Schlussfolgerung helfen. Ein Beispiel für eine solche Ungewissheit kann die Frage sein, ob eine bestimmte medizinische Behandlung einen bestimmten Effekt hat oder nicht. Im letzteren Fall könnten wir auch eine randomisierte kontrollierte Studie oder eine datenbasierte Kausal-Folgerungs-Methode einfügen, um uns zu informieren.
Selbst der beste Werkzeugkasten befreit uns nicht von den Entscheidungen
KI-Algorithmen sind großartige Werkzeuge, um Muster in unseren Daten zu erkennen, basierend auf diesen Mustern Vorhersagen zu treffen und Daten zu klassifizieren, um uns schließlich Entscheidungsmöglichkeiten aufzuzeigen. Sie sind zusätzliche Werkzeuge innerhalb unseres wissenschaftlichen Inferenz-Werkzeugkastens, die von unseren Vorgängern mit großartigen Werkzeugen gefüllt wurde und von unseren Nachkommen mit weiteren großartigen Werkzeugen gefüllt wird. Der Werkzeugkasten wird uns unseren Weg durch die Komplexität erhellen, uns Entscheidungswege aufzeigen. Aber am Ende des Tages wird uns der Werkzeugkasten nicht von den Entscheidungen befreien. Wie Morpheus sagen würde:
