
The following is a short version of a much longer Blog post on the topic that I wrote before.
“I know that I know nothing”
– Socrates, according to Plato –
“I think, therefore I am”
– René Descartes –
In the last weeks the allegory of the cave came often to my mind while investigating most recent approaches to better understand the learning mechanism within Deep Neural Networks (DNNs).
As humans we observe the world through our natural senses and our brain then makes sense of that information. As a consequence, all theories and models that we build based on our observations are constructed under uncertainty.

Information Theory and Information Bottleneck Theory
In order to measure and quantify uncertainty in a mathematically rigorous way, information theory was proposed by Claude Shannon in 1948. The key measure of information theory is the information entropy, also often called just entropy.
In the context of the cave allegory, the act of breaking free from the cave is an attempt to maximally minimize entropy by acquiring the “true” causes of the observed phenomena.
Information theory is also at the heart of a promising theoretical approach to Deep Learning. This is called the “Information Bottleneck” (IB) theory and was proposed and developed by Naftali Tishby and colleagues from the Hebrew University at Jerusalem very recently. In summary, the IB theory describes Deep Learning as a two-phase process to compress a huge amount of data with all its features into a shorter representation.
A Tradeoff Between Compression and Prediction
As a visual example let us consider a trained DNN as a representation of a large image data set containing object classes (humans, animals, cars and other objects). Later feeding another image as input of a such trained DNN shall give as output the decision if there are one or more of the object classes present in the image. Tishby and Zaslavsky formulate in their 2015 paper, Deep Learning and the Information Bottleneck Principle, “the goal of deep learning as an information theoretic tradeoff between compression and prediction.”
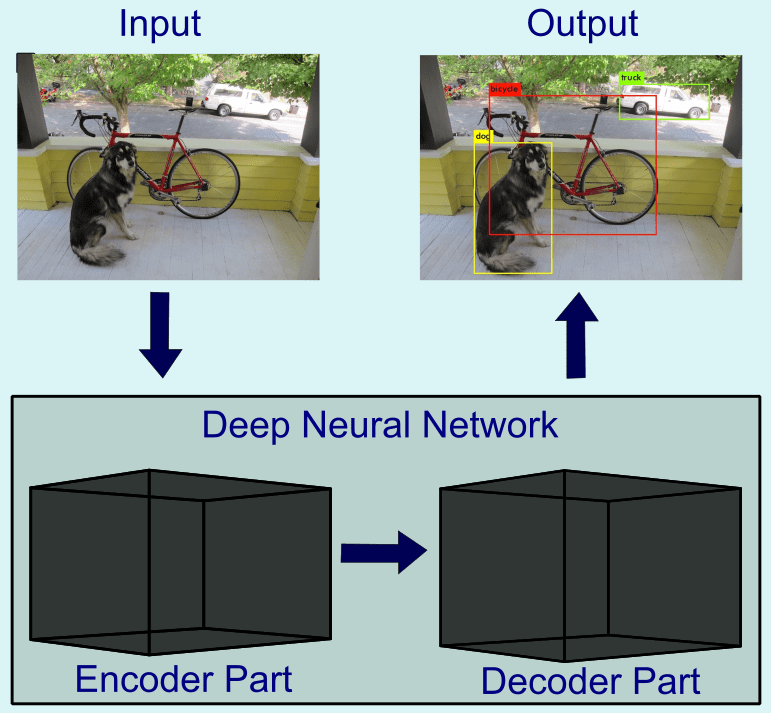
A more abstract schematic of such a DNN is visualized in Figure 1. The first part of the DNN, the Encoder, extracts relevant information from the input data set. The second part, the decoder, classifies the output (human, animal, other objects) from the extracted features represented within the encoder. This DNN was trained on images to extract the specific classes together with the corresponding bounding boxes around the objects in the image. The abbreviation “YOLO” stands for “You only look once”, specifying that the algorithm is able to process the image once and extract all objects in parallel in one pass through the DNN.
The Information Plane
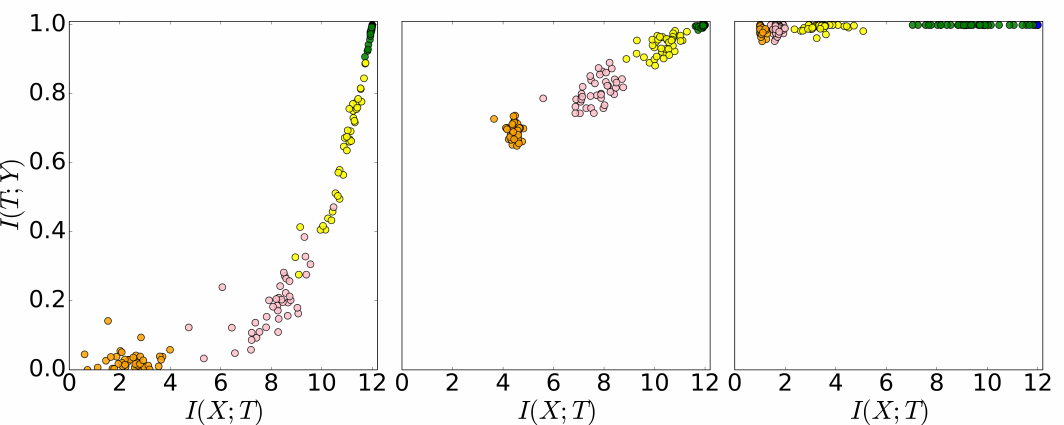
To better understand how the Information Bottleneck theory captures the essence of deep learning, Tishby and co-workers utilized the concept of information plane as a two-dimensional Carthesian plane (see Figure 2). Here, the x-axis shows the information content encoded into the network about the input, while the y-axis quantifies the information content encoded about the output class within the network.
The information plane lets us visualize the whole life cycle of tens to hundreds of neural networks with different architectures and different initial weights trained on the same data set (input and output).
A Forgetting Procedure
Generally, after many learning epochs, information about the input within all layers is gradually decreasing. One can imagine this process as a kind of forgetting procedure. Let us consider the example of predicting if in any image there are humans or not. In the phase where the network training is just involved with fitting input images to the label human or not, the network might just consider any type of image feature as relevant for the classification.
For example, it may be that the first batches of the training data set contain mostly images of people at streets in cities. Hence, the network learns to consider the high-level feature “street” as relevant for classifying humans in images. Later it might see other samples with people inside houses, people in the nature and so on. It shall then “forget” the specific feature “street” as relevant for predicting human in the image. We can somehow say that the network now has learned to abstract away the specific surrounding environment features to an extent that it generalizes well over several environments where we expect to observe humans.
Thanks to the effort by Tishby and colleagues, we now have with the IB theory one promising candidate for a more rigorous study of deep learning at our disposal. The parameters of modern DNNs reach up to billions in number. The IB theory delivers a description picture with two parameters (the two axes of the information plane) instead of the millions to billions of connection parameters of a DNN.